Introduction
If you are not aware of the term Teams Topologies. It is a terminology popularised by Manuel Pais and Matthew Skelton.
You can read up more about it here: https://teamtopologies.com
In this blog I explore how DevOps as an approach has gone wrong in many organisations, and why applying some thought to the way your teams interact is crucial for success.
What happened to the DevOps approach?
One common theme I have observed is different teams have a different view of what DevOps actually is. Some teams think it is just CI/CD tooling, automation. Others view it as a rebrand of infrastructure and ops teams.
What DevOps meant to me
To me, the original philosophy behind DevOps carried a lot of weight.
Recalling my time as a Lead Developer, all the typical warning signs that development and operations had friction fundamentally boiled down to:
- Lengthy release process leading to failed releases
- Lack of automated testing leading to buggy software
- Inconsistent environments leading to troubleshooting and “It works on my laptop” cries
- Poor monitoring, logging leading to Operations rejecting releases
- The throw it over the wall mentality
Common goals
The key denominator was both teams served the end customer/product. And with this came a responsibility to deliver value for them in terms of software quality with operational excellence.
For me the principles and philosophy could be summed up as
- Reducing waste (Lean development)
- Automating manual steps via CI/CD pipeline
- Building consistent environments using concepts such declarative infrastructure (IaC) and configuration management
- Paying attention to observability, and knowing what to measure and report on
- Shorten and amplify feedback loops between ops and development. Failing fast.
The Cloud and DevOps
When I started consulting in the area of Cloud (mostly Azure) I assumed that Cloud and DevOps was a great match. I mean, a programmable Cloud meant automating platforms, software releases, Infrastructure As Code were all being made easier with CI/CD tooling.
The term “You Built It, You Run It”, kind of sounded like a good idea with a plethora of tools such as Azure Pipelines, GitLab, GitHub engineering teams were trying to automate everything!
Silos are back!
However, as I worked on numerous engagements I realised that across the industry technology, tooling was hiding the underlying issues between teams.
Teams were not evolving their interactions with each other with the pace of the technology change. Rather they were creating new silos!
So rather then bring the teams closer, new silos became to emerge.
Sweeping the underlying issues under the carpet
However, with organisations adopting AWS, GCP and Azure some started to
- Increase length of feedback loops rather than shorten them
- Create silos instead of reducing them
- Decrease team interaction rather than increase them
Building great products with cross functional teams relies on feedback loops that are small, requires continuous improvement and constant collaboration.
But, as organisations started to venture into building new capabilities in their Cloud, they forget that the real outcome is to bring teams closer in collaboration to deliver an outcome for their end users – the customer!
The result has been further separation, as Infrastructure focused DevOps engineers started to become the gate keepers of Cloud environments (in regulated industries for example) and the team to go to for building CI/CD pipelines? Developers waited eagerly on the new shiny Cloud environment they were promised!
Understanding team topologies -the traditional stream aligned teams
Team topologies talks about these common issues as fundamentally the flow of work between different teams. The first team they talk about is the Stream aligned team.
This is the traditional engineering team aligned to a particular software, product. They typically own the feature development and maintenance of the software.
Try to evolve team interactions
Before you jump into building a “Platform” and dive into the deep with Platform engineering take a step backward. Ask your teams the question have we tried everything to improve the flow between the teams building and supporting our Software?
If the answer is “No”. Then take a look at how your teams can interact better.
In Team topologies there are two teams which may help your stream aligned team.
Platform team
Now a platform team could be specialists in Kubernetes, a particular cloud provider such as AWS, Azure or GCP.
Their goal is to reduce the cognitive load of whatever platform the stream aligned teams uses. Strategies involved and not limited to include:
- Understand the requirements of the stream aligned team, working closely with Senior developers to make sure Kubernetes environments are seamless to consume and designed to meet the software requirements
- Collaborate with Senior developers, providing self service IaC modules that are reusable building blocks, making the path to production environments a self service workflow.
Enabling team
An enabling team, could be a team of engineers skilled in the ideas of DevOps, automation, configuration management and IaC. For example, a typical example could be a team struggling with these skills and therefore their software delivery is hindered.
A common issue maybe inconsistent environments. By collaborating, and helping the team create consistent environments using Terraform, the enabling team can improve this key outcome.
Conclusion
As the industry evolves, new patterns emerge, it is clear that to drive success involves more interaction, collaboration instead of increased silos.
Team topologies is not something you can use as a cookie cutter to tackle the problem. At the center is the challenge of people, process and technology.
However, what is clear based on your organisation (different needs and contexts) you can adapt to see which Team topology interaction or team can help you delivery better software delivery outcomes.







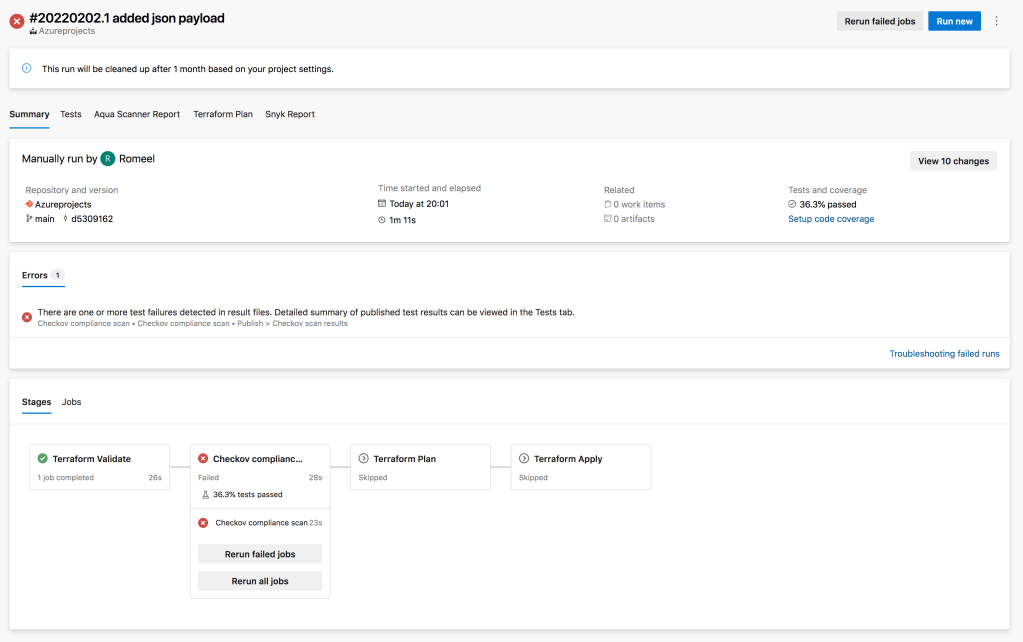
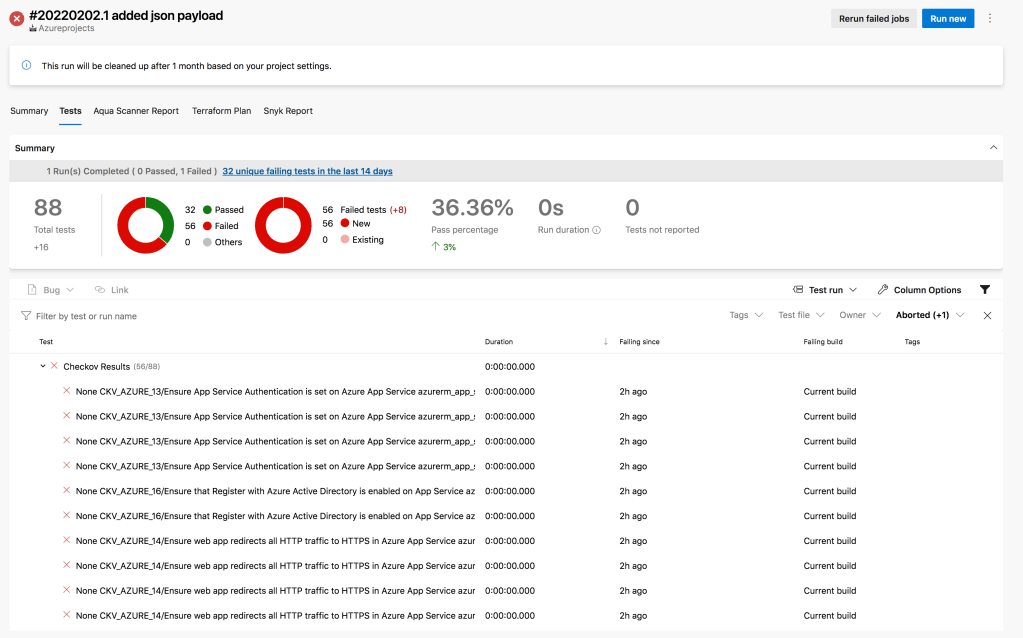
 AKS
AKS